Comparing HLS and HDL Implementations of the Fast Fourier Transform (FFT)
VHDL was introduced in 1981, followed by Verilog in 1984. Both were primarily introduced as a way to document and simulate the behavior of digital circuits. As the languages became standardized and more broadly adopted, tools became more affordable and capable, eventually leading to the use of these languages for circuit synthesis in the 1990’s and 2000’s. These Hardware Description Languages (HDLs) revolutionized the world of digital logic design, significantly reducing the time it takes to bring products to market over more traditional (at the time) schematic-based approaches.
High-Level Synthesis (HLS) takes this a step further by allowing algorithmic descriptions that abstract away the cycle-by-cycle description of RTL, further reducing the time it takes to bring products to market. BittWare reported an impressive decrease in time to market, from one month using RTL to just one week using HLS, also noting some unexpected performance improvements from the HLS implementation.
As an FPGA module manufacturer, we’re continually tracking trends in FPGA and PCB technology, including the tools our customers use in their development processes. Naturally, we have been interested in the potential applications, benefits, and pitfalls of HLS.
Recently, one of our engineers decided to create an easy-to-use, scalable, streaming Fast Fourier Transform (FFT) library using AMD-Xilinx’s Vitis HLS. Our source code is available on our GitHub repository. To our surprise, it only took roughly one week to put together our FFT library. This is a significant improvement compared to what an RTL implementation would have taken, which could have taken weeks or months. Admittedly, our initial approach (we’re calling the “naive approach”) is very closely based on common software implementations and leaves a lot of room for optimization.
Afterwards, we conducted a comparison of the utilization and performance of our library against AMD-Xilinx’s RTL FFT LogiCORE IP, using comparable parameter configurations. For additional information about the configuration used and a more comprehensive analysis, please refer to our library’s utilization page. To provide an overview of the comparison, we have included a graph below that summarizes the utilization and performance results obtained from that page:
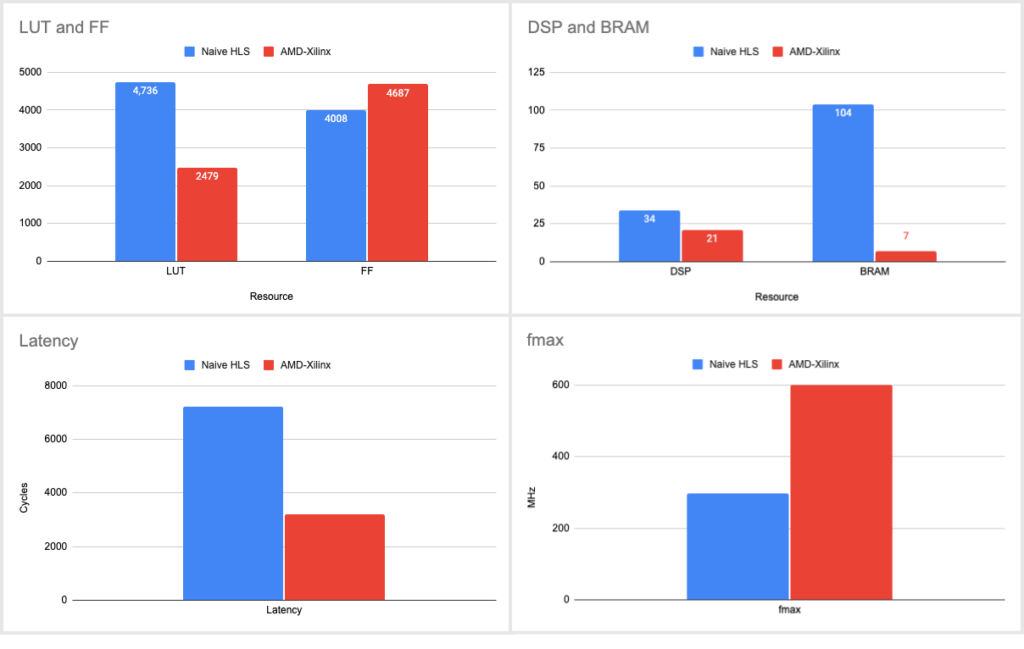
While our HLS implementation underperformed AMD-Xilinx’s RTL implementation in both utilization and performance metrics, it was still within a modest range. For non-critical assets, time to market is more valuable to us than utilization or performance, which is why we were impressed with the HLS results.
Bottom Line
Our hardware products are all about achieving first success faster — getting to prototype and proof-of-concept as quickly as possible, then iterating and refining to reach a production, market-viable platform. HLS dovetails with this hardware vision perfectly. If hardware, software, and gateware teams can operate in parallel with as few pipeline stalls as possible, that’s a great utilization of development resources.
Based on our evaluation, HLS is likely to play a larger part in several ongoing developments at Opal Kelly.
In a future blog post, we’ll introduce you to our FFT-based signal generator sample. We took the FFT “on the road”, mated it to the XEM8320 development platform, and our high-speed SYZYGY data converter to create a simple, but effective, signal generator. Stay tuned!